Kaption: Nakładka OCR, która Tłumaczy Dialogi Hoyoverse w Czasie Rzeczywistym
Genshin Impact i Honkai: Star Rail mają ogromne społeczności w Polsce, ale żadna z tych gier nie doczekała się polskiej lokalizacji. Gracze, którzy angielski znają tylko okazjonalnie, tracą niuanse fabularne, imiona bóstw, żarty w dialogach i wątki poboczne. W grach, które opierają się na długich rozmowach NPC i rozbudowanym świecie, to nie drobiazg — to połowa tego, za co się je lubi.
Kaption (wcześniej "Genshin-Subtitles") to aplikacja desktopowa na Windows, która czyta dialogi wprost z okna gry, dopasowuje rozpoznany tekst do wewnętrznej listy linii gry, a następnie pokazuje polskie tłumaczenie w nakładce nad oknem dialogu. Bez modów. Bez haczenia pamięci. Bez streamowania obrazu do chmury. Aplikacja czyta piksele tak, jak robi to Windows Snipping Tool, i cała reszta dzieje się lokalnie na Twojej maszynie.
To studium przypadku pokazuje, jak zbudowaliśmy Kaption od strony technicznej — potok OCR na GPU, trzystopniowy matcher, który radzi sobie z typowymi pomyłkami rozpoznawania, predykcję kolejnej linii dialogu, ochronę pakietów tłumaczeń i dystrybucję przez Velopack. Po drodze opiszę też błędy, które kosztowały nas trzy weekendy, oraz decyzje, które wydawały się oczywiste dopiero z perspektywy czasu.
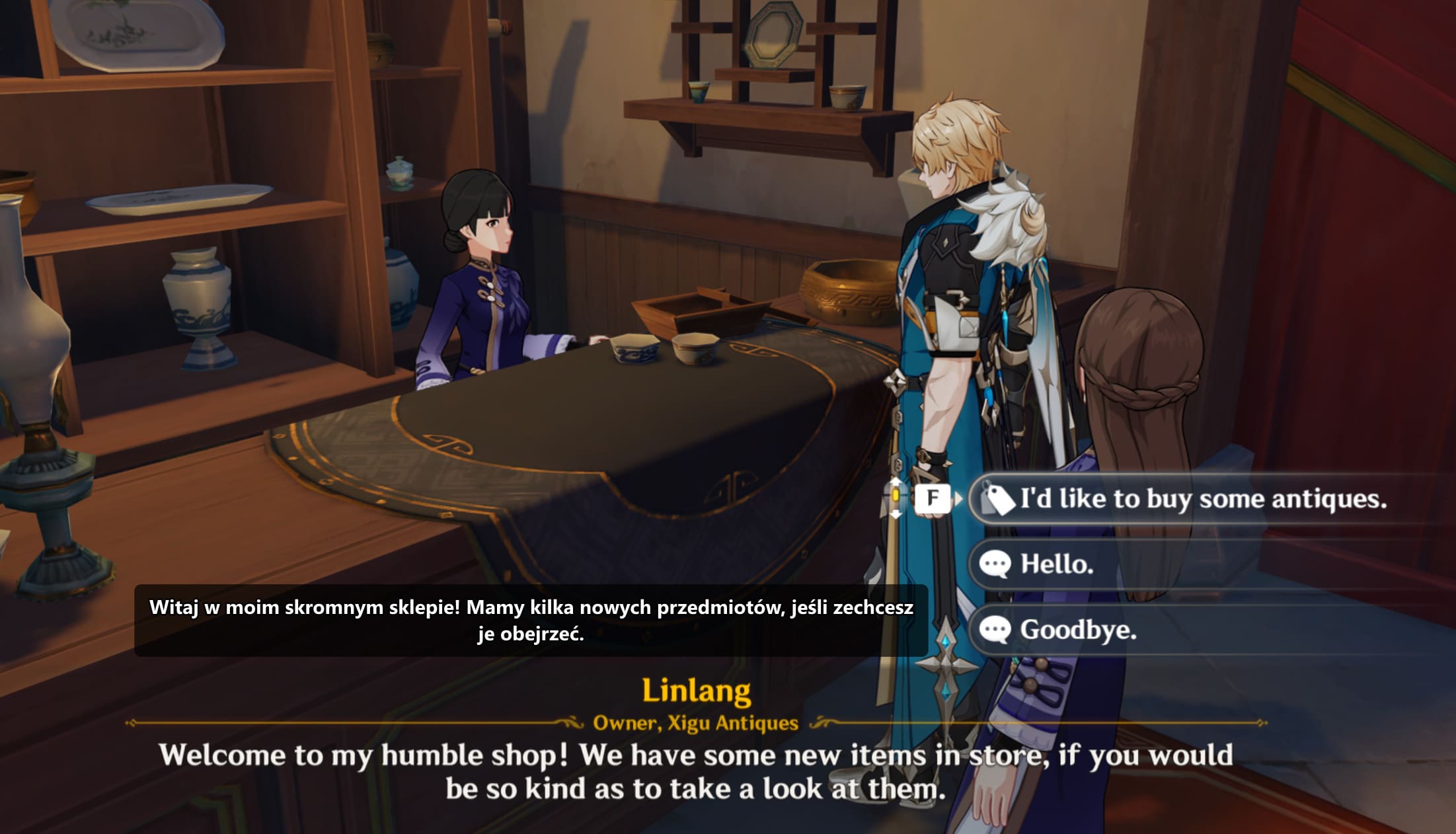
Problem: Luka Lokalizacyjna i Złe Rozwiązania Zastępcze
Hoyoverse lokalizuje swoje gry na kilkanaście języków, ale polski nie jest na tej liście. W grach fabularnych, gdzie jedno zadanie potrafi mieć setki linii dialogu, bariera językowa skraca rozgrywkę do rzucania okiem na minimapę i klikania "pomiń". Znika cały kontekst — kto do Ciebie mówi, dlaczego, czego od Ciebie chce i co się właśnie wydarzyło w świecie gry.
Społeczność próbowała to rozwiązać na własną rękę, ale każda z istniejących ścieżek ma swoją cenę. Tłumaczenia na streamie wymagają drugiego monitora i osoby, która na żywo tłumaczy scenę — działa, ale nie w nocy o drugiej, gdy siadasz do gry po pracy. Mody, które podmieniają pliki gry, łamią sygnatury i potrafią zahaczyć o systemy anti-cheat. Zewnętrzne programy, które czytają pamięć procesu gry, budzą podobny niepokój i padają przy każdej aktualizacji.
Chcieliśmy narzędzia, które będzie czyste z perspektywy zasad korzystania z gry, odporne na patche i na tyle szybkie, żeby tłumaczenie pojawiło się zanim gracz zdąży przeczytać oryginał. Żadne z istniejących rozwiązań nie spełniało tych trzech warunków jednocześnie.
Dlaczego Nakładka, a nie Mod
Decyzja o formie aplikacji zapadła najwcześniej i była w zasadzie bezdyskusyjna. Nakładka pozostaje całkowicie poza procesem gry — nie musi wiedzieć o jej wewnętrznej strukturze, nie wymaga uprawnień administracyjnych i nie "rozmawia" z klientem gry na żadnym poziomie. Jedyne, co robi, to odczytuje piksele wyświetlone na ekranie i rysuje własne okno nad oknem gry.
Co to konkretnie oznacza
- ▸Zero modyfikacji plików gry. Katalog instalacji Genshin pozostaje nietknięty. Kaption nie wie, gdzie jest zainstalowany, i nie musi wiedzieć.
- ▸Zero czytania pamięci procesu. Aplikacja nie otwiera handle'a do procesu gry, nie używa ReadProcessMemory, nie haczy funkcji w DLL. To rozwiązanie łamliwe przy każdym patchu i wątpliwe prawnie — omijamy je całkowicie.
- ▸Zero hooków sieciowych. Nie podsłuchujemy ruchu, nie podrabiamy pakietów, nie siedzimy między klientem a serwerem. Cały ruch sieciowy gry idzie dokładnie tam, gdzie ma iść.
- ▸Czysty reset. Zamknięcie Kaption nie zostawia po sobie żadnego śladu w grze. Gra nawet nie wie, że Kaption działał.
Ta decyzja ma oczywiście koszty. Musimy rozpoznać tekst z obrazu zamiast po prostu go przeczytać z pamięci, a OCR bywa zawodny. O tym, jak sobie z tym radzimy, za chwilę. To podejście ma też naturalny związek z nowoczesnymi aplikacjami WPF, które pozwalają zbudować warstwowe okno z obsługą click-through — gracz klika "przez" nakładkę wprost w okno gry.
Potok od Pikseli do Tłumaczenia
Kaption działa w pięciu krokach, które powtarzają się dziesięć razy na sekundę. Każdy z nich ma budżet czasowy i osobny mechanizm zabezpieczający przed śmieciowymi wynikami. Całość zamknięta jest w twardej pętli czasu rzeczywistego — jeśli któryś krok się nie zmieści, porzucamy klatkę i czekamy na następną.
Pięć kroków, jeden cykl
- 1. Przechwycenie klatki. DXGI Desktop Duplication API kopiuje bufor okna gry z GPU. W razie, gdy DXGI nie zadziała (niektóre kompozycje okien, specyficzne sterowniki), spadamy na GDI. Typowy koszt: ~2 ms.
- 2. Wymaskowanie własnej nakładki. Ponieważ renderujemy tłumaczenie nad oknem gry, musimy wyciąć z przechwyconego obrazu piksele, które sami narysowaliśmy. Inaczej OCR przeczyta polski tekst, próbuje go dopasować do angielskiej TextMap i zwariuje. O tej pułapce piszemy dalej w sekcji "Czego nauczyliśmy się po drodze".
- 3. Binaryzacja i OCR. PaddleOCR w formacie ONNX uruchomiony na DirectML. Na GPU rozpoznanie pojedynczej klatki schodzi poniżej 10 ms. Na ścieżce CPU (gdy DirectML nie jest dostępny) mieścimy się w 40–80 ms.
- 4. Dopasowanie do TextMap. Trzy etapy: SymSpell (~5 µs), selekcja kandydatów n-gramami, a na końcu ważony Levenshtein rozstrzyga między finalistami. Cały matcher mieści się w pojedynczych milisekundach.
- 5. Render. Warstwowe, przezroczyste okno WPF rysuje polski tekst dokładnie w obszarze okna dialogu. Poniżej 1 ms, ponieważ renderujemy tylko, gdy zmiana jest konieczna.
Typowy budżet end-to-end na średnim sprzęcie to około 80 ms od pojawienia się nowej linii w grze do wyświetlenia tłumaczenia. W praktyce gracz rzadko dostrzega to opóźnienie, bo linie dialogowe pojawiają się z efektem "maszyny do pisania" — znaki dolatują stopniowo, a tłumaczenie bywa gotowe zanim litery przestaną się dopisywać.
W architekturze Kaption biegną dwa niezależne timery. Jeden odpala OCR co 100 ms. Drugi odświeża UI co 200 ms. Dzięki temu rendering nakładki pozostaje płynny nawet wtedy, gdy OCR akurat pracuje, a pojedynczy dłuższy cykl rozpoznawania nie zamraża tekstu na ekranie. To podejście bliskie temu, co opisywaliśmy w kontekście aplikacji czasu rzeczywistego: rozdzielenie warstwy akwizycji danych od warstwy prezentacji upraszcza obie strony.
Matcher to Najciekawsza Część
OCR nigdy nie zwraca dokładnie tego, co jest na ekranie. Rozpoznaje "l" jako "1", myli "rn" z "m", "O" z "0", gubi kropki po skrótach. Naiwne porównywanie rozpoznanego tekstu z TextMap gry po prostu nie zadziała. Zamiast tego mamy trzy etapy, każdy szybszy od następnego i każdy szerszy w swojej tolerancji błędów.
Etap 1: SymSpell (około 5 µs)
SymSpell to algorytm symmetric-delete spellcheck — zamiast porównywać każdą parę stringów znak po znaku, przygotowuje wcześniej słownik usunięć i szuka po hashu. Dla 500 000+ linii dialogowych w indeksie pojedyncze zapytanie schodzi do pojedynczych mikrosekund. Jeśli OCR-owana linia trafia w SymSpell bezpośrednio, kończymy na tym etapie. Dla typowego polskiego gracza to około 70–80% dopasowań.
Etap 2: Selekcja kandydatów n-gramami
Gdy SymSpell nie trafi, musimy zawęzić pole. Zamiast liczyć Levenshteina dla wszystkich 500 000 linii, używamy trigramowego indeksu odwróconego. Linia dialogowa rozbijana jest na trójki znaków; szukamy kandydatów, którzy dzielą najwięcej trigramów z naszym rozpoznanym tekstem. Zwykle zostaje nam kilkaset linii zamiast pół miliona — i dopiero na nich uruchamiamy trzeci etap.
Etap 3: Ważony Levenshtein
Klasyczny Levenshtein traktuje każdą pomyłkę jednakowo — zamiana "l" na "1" kosztuje tyle samo, co zamiana "l" na "q". W OCR to bzdura. Nasza implementacja używa macierzy kosztów, w której typowe pomyłki mają wagę bliską zeru, a nietypowe — wagę pełną. Kilka przykładów:
cost('l', '1') = 0.1 // wysokie i chude, często mylone
cost('O', '0') = 0.1 // koło okrągłe vs cyfra
cost('rn', 'm') = 0.2 // klasyk OCR
cost('I', 'l') = 0.1 // bez szeryfów nie do rozróżnienia
cost('a', 'q') = 1.0 // zwykłe dwa różne znakiPróg akceptacji ustawiliśmy empirycznie po przeanalizowaniu kilkuset godzin rozgrywki. Jeśli najlepszy kandydat przekracza próg błędu, odrzucamy klatkę zamiast pokazać złe tłumaczenie — w fabule pomyłka wprowadza więcej szumu niż brak tłumaczenia w ogóle. Efekt: trafność dopasowania w rzeczywistej rozgrywce oscyluje wokół 97%.
Cała struktura matchera jest świetnym miejscem, żeby zastosować techniki z naszego przewodnika po testowaniu wydajności i optymalizacji — każdy z trzech etapów ma swój benchmark, a regresja w którymkolwiek zapala czerwoną lampkę w CI.
Graf Dialogów i Predykcja Kolejnej Linii
Dialogi w grach Hoyoverse nie są losowe. Mają strukturę: linia wprowadzająca, opcje odpowiedzi gracza, reakcje NPC, linia domykająca. Kaption ładuje ten graf razem z pakietem tłumaczeń i używa go do predykcji — gdy rozpoznamy linię X, wiemy, że kolejna będzie jedną z niewielu konkretnych linii Y, Z, W.
Pre-cache oznacza, że zanim OCR zdąży rozpoznać nową linię, jej tłumaczenie jest już przygotowane w pamięci. W wielu przypadkach tłumaczenie pojawia się dosłownie w tej samej klatce, w której linia staje się widoczna w grze — OCR tylko potwierdza, którą z przewidywanych opcji faktycznie wybrała gra.

Bonusowa korzyść: graf dialogów pozwala też odróżnić dwie identyczne linie, które pojawiają się w różnych zadaniach. Mała uwaga w kontekście — wystarczy, że wiemy, w którym łuku fabularnym jesteśmy — i pokazujemy właściwy przekład zamiast arbitralnie pierwszego z brzegu.
Jakość Tłumaczenia — To Nie Google Translate
Tłumaczenia w Kaption są generowane przez model AI linia po linii, z pełnym kontekstem: kto mówi, do kogo, w którym zadaniu, jakie były poprzednie dwie–trzy linie. To znaczy, że "Lord" w ustach szlachcica w Mondstadt zostaje przełożony inaczej niż "Lord" w pojedynku magicznym, a imiona własne, regiony i terminy gry pozostają spójne przez całą grę.
W praktyce przekłada się to na trzy rzeczy. Po pierwsze, gra czyta się jak książka, a nie jak automat — akapity mają sens, żarty zostają zachowane, a kwestie postaci brzmią jak one. Po drugie, terminologia nie skacze: ta sama broń, ten sam region, ten sam element mają zawsze tę samą nazwę. Po trzecie, jakość przekładu nie zależy od jakości OCR — dopasowanie trafia w konkretny wiersz w TextMap, a my pokazujemy wcześniej przygotowane tłumaczenie.
Pipeline tłumaczeń działa offline w środowisku Node i Python i publikuje paczki na R2. Szczegóły technologiczne zostawiamy na koniec, ale istotne jest jedno: gracz ściąga gotowy pakiet i dostaje stabilny przekład bez obciążania swojej maszyny pracą modelu AI.
Local-first, Prywatność, Bezpieczeństwo
Kaption działa w całości lokalnie. OCR liczymy na Twoim GPU (albo CPU), dopasowanie do TextMap liczymy w Twojej pamięci, tłumaczenie masz zrzucone na dysk w pakiecie. Żadna klatka z gry nie opuszcza Twojej maszyny. Do chmury idą tylko dwie rzeczy: sprawdzenie, czy jest nowa wersja aplikacji, i — jeśli włączysz tę opcję — anonimowy raport o awarii. Telemetria jest domyślnie wyłączona.
Pakiety tłumaczeń zabezpieczamy AES-256-CBC z dodatkowym HMAC-SHA256 i kluczem pochodnym PBKDF2 związanym z maszyną. Nie chodzi o paranoję, tylko o prostą ekonomię: pakiety są wynikiem wielu godzin pracy modelu AI i ludzkiej redakcji, a ich bezpośrednie kopiowanie obniżyłoby wartość projektu. Dla użytkownika końcowego jest to niezauważalne — pakiet działa po instalacji.
Aplikacja nie czyta pamięci gry, nie wstrzykuje DLL, nie haczy funkcji systemowych. Z perspektywy systemu operacyjnego wygląda tak samo jak Snipping Tool: proces użytkownika, który zrzuca obraz z ekranu i rysuje własne okno. Dzięki temu podejście do obserwowalności i monitoringu w produkcjiogranicza się do rozsądnych podstaw — logi aplikacyjne, raporty awarii, nic więcej.

Dystrybucja i Aktualizacje
Aktualizacje idą przez Velopack. Wybraliśmy go, bo robi delta-updates — ściąga tylko zmienione fragmenty aplikacji, a nie cały pakiet od nowa. Feed aktualizacji siedzi na Cloudflare R2: zero opłat za egress, dobre latencje w Europie i spokojne życie, gdy pojawi się skok ruchu po patchu gry.
Instalator jest samowystarczalny — nie wymaga osobnego instalowania .NET 10 Desktop runtime, nie prosi o uprawnienia administratora. Pobierasz plik, klikasz, aplikacja ląduje w profilu użytkownika. Instalacja waży około 350 MB (w tym .NET runtime) i po niej Kaption pracuje off-line — do działania nie potrzebuje internetu poza pierwszym pobraniem pakietu tłumaczeń.
Kreator konfiguracji pokazuje się raz, przy pierwszym uruchomieniu. Wykrywa okno gry, proponuje prostokąt obszaru dialogu na podstawie znanej rozdzielczości i pozwala poprawić go ręcznie. Dla typowego gracza to pięć kliknięć.
Crash reports (opt-in) idą do Sentry. Nie zbieramy zawartości ekranu ani treści dialogów — tylko stack trace, wersję aplikacji, model GPU i rozdzielczość. Doświadczenia z wcześniejszych projektów pokazały, że to wystarczy, żeby w 90% przypadków odtworzyć problem lokalnie.
Liczby, Które się Liczą
Zamiast okrągłych przymiotników, kilka konkretnych metryk. Wszystkie pochodzą z pomiarów na średnim sprzęcie testowym (Ryzen 5 5600, GTX 1660 Super, 16 GB RAM) albo z rzeczywistej rozgrywki testerów.
Opóźnienie end-to-end
Od klatki gry do wyrenderowanego tłumaczenia
Trafność dopasowania
W rzeczywistej rozgrywce, po trzech etapach matchera
Linii TextMap w indeksie
Dialogi, UI, nazwy, opisy zadań, wszystko co gracz zobaczy
Fast-path SymSpell
Pojedyncze zapytanie w słowniku dopasowań
Obsługiwane gry
Genshin Impact i Honkai: Star Rail, profile OCR per gra
Języków potencjalnie
Jeśli istnieje pakiet, Kaption go obsłuży

Stack Technologiczny — Dlaczego Takie Wybory
Każda warstwa Kaption ma konkretne uzasadnienie. Nie wybieraliśmy najnowszych technologii dla zasady — wybieraliśmy te, które rozwiązują problem bez zaciągania niepotrzebnego długu. Projekt korzysta z nowoczesnej platformy .NET 10, ponieważ cały ekosystem desktopowy Microsoftu wreszcie złożył się w spójną całość.
Desktop i OCR
.NET 10 / C# 12+, WPF Desktop
Dlaczego: WPF daje warstwowe, przezroczyste okna z obsługą click-through bez walki z WinAPI na niskim poziomie. Nowszy .NET oznacza lepszą wydajność GC i natywny dostęp do nowoczesnych API Windows. C# 12 upraszcza kod potoku OCR.
PaddleOCR przez ONNX Runtime + DirectML
Dlaczego: PaddleOCR świetnie radzi sobie z mieszanym tekstem CJK i łacińskim, co bywa istotne w menu i napisach Hoyoverse. ONNX Runtime pozwala uruchamiać model bez instalowania PaddlePaddle, a DirectML to naturalna ścieżka GPU na Windows, która działa na AMD, NVIDIA i Intel bez osobnych buildów.
DXGI Desktop Duplication API (+ fallback GDI)
Dlaczego: DXGI kopiuje framebuffer wprost z GPU — rzędy wielkości szybciej niż BitBlt. GDI trzymamy jako fallback dla starszych konfiguracji i specyficznych kompozycji pulpitu.
Matcher i Dane
SymSpell (symmetric-delete spellcheck)
Dlaczego: Rzędy wielkości szybszy od naiwnego Levenshteina dla dużych słowników. Dla 500 000 linii naiwne podejście dawało pojedyncze sekundy na dopasowanie. SymSpell zszedł do mikrosekund i zrobił resztę architektury możliwą.
Własna implementacja ważonego Levenshteina
Dlaczego: Gotowych implementacji z macierzą kosztów pod OCR nie było, a to jeden z niewielu kawałków, gdzie "napiszmy sami" naprawdę się zwróciło. Koszt utrzymania minimalny, kontrola nad wagami pełna.
Hashmapa 500 000+ linii + graf dialogów
Dlaczego: TextMap i graf serializujemy do zwartego formatu binarnego i ładujemy raz na starcie. Po załadowaniu wszystko operuje na wskaźnikach do tej samej pamięci — zero dodatkowych alokacji w hot-pathu.
AES-256-CBC + HMAC-SHA256 + PBKDF2
Dlaczego: Standardowe prymitywy z .NET — bez wynajdywania koła. PBKDF2 wiąże klucz z maszyną, HMAC chroni integralność, CBC daje szyfrowanie. Razem wystarczająco, żeby pakiety nie były trywialne do kopiowania między maszynami.
Dystrybucja i Platforma
Velopack (delta-updates)
Dlaczego: Aktywnie utrzymywany następca Squirrel.Windows. Instalacja bez uprawnień administracyjnych, delta-updates, prosta konfiguracja feedu, dobry developer experience.
Cloudflare R2 (feed + pakiety)
Dlaczego: Kompatybilny z S3, zero opłat za egress, dobre latencje globalnie. Dla darmowego narzędzia community to istotna różnica w kosztach.
Sentry (opt-in crash reports)
Dlaczego: Dojrzała obsługa .NET, grouping stack traces, możliwość przypisywania releasu. Zbieramy minimum: stack trace, wersja, GPU, rozdzielczość.
Pipeline tłumaczeń: Node + Python, Astro + Tailwind, Supabase
Dlaczego: Node obsługuje orkiestrację wywołań do modelu AI i publikację pakietów, Python odpala narzędzia lingwistyczne (tokenizery, porównania translacji). Landing page to Astro 5 z Tailwindem — statyczne, szybkie, tanie w hostowaniu. Supabase trzyma listę waitlist i głosowania community.
Czego Nauczyliśmy się po Drodze
Trzy historie, które nie zmieściły się w materiale marketingowym, ale w naszej pamięci zostały na długo.
1. Pętla zwrotna OCR-a na własnej nakładce
Pierwszy prototyp padł po pięciu minutach testów. Nakładka renderowała polskie tłumaczenie, OCR w kolejnej klatce rozpoznawał to tłumaczenie razem z oryginalnym tekstem, matcher dostawał mieszankę polsko-angielską i wypluwał losowe dopasowania. Klasyczny feedback loop. Rozwiązanie okazało się proste, ale wymagało zmiany architektury: maskujemy obszar nakładki w przechwyconym obrazie zanim cokolwiek powędruje do OCR. To krok 2 w pięciostopniowym potoku opisanym wcześniej — i bez niego cała reszta jest bezużyteczna.
2. Efekt maszyny do pisania zmusił nas do bramki stabilności klatki
Linie dialogowe w Hoyoverse wjeżdżają znak po znaku. Jeśli OCR złapie klatkę w połowie animacji, rozpozna na przykład "The knight of favor" zamiast "The knight of favonius" — i matcher trafi w inny wiersz TextMap. Początkowo próbowaliśmy większych progów błędu, ale to produkowało fałszywe dopasowania w innych miejscach. Zajęło nam trzy weekendy, zanim zrozumieliśmy, że właściwa odpowiedź to bramka stabilności klatki — porównujemy dwie kolejne klatki OCR i wypuszczamy wynik dopiero, gdy obie zwracają ten sam tekst. Kosztuje jedną ramkę czasu reakcji, ale eliminuje problem całkowicie.
3. Historia z pakowaniem, którą niedoszacowaliśmy
W pierwotnym planie instalator Kaption miał sprawdzać, czy .NET 10 Desktop runtime jest obecny, i prosić użytkownika o jego zainstalowanie, jeśli nie był. Szybko okazało się, że to zły pomysł: gracze spodziewają się doświadczenia "pobierz, kliknij, działa", a nie trzech kroków z drugim instalatorem pośrodku. Przerzucenie na self-contained installer dodało około 60 MB do pobierania, ale zlikwidowało 80% zgłoszeń od użytkowników testowych. Lekcja na przyszłość: na desktopie każdy krok instalacji to punkt porzucenia — opłaca się ściąć je do zera.
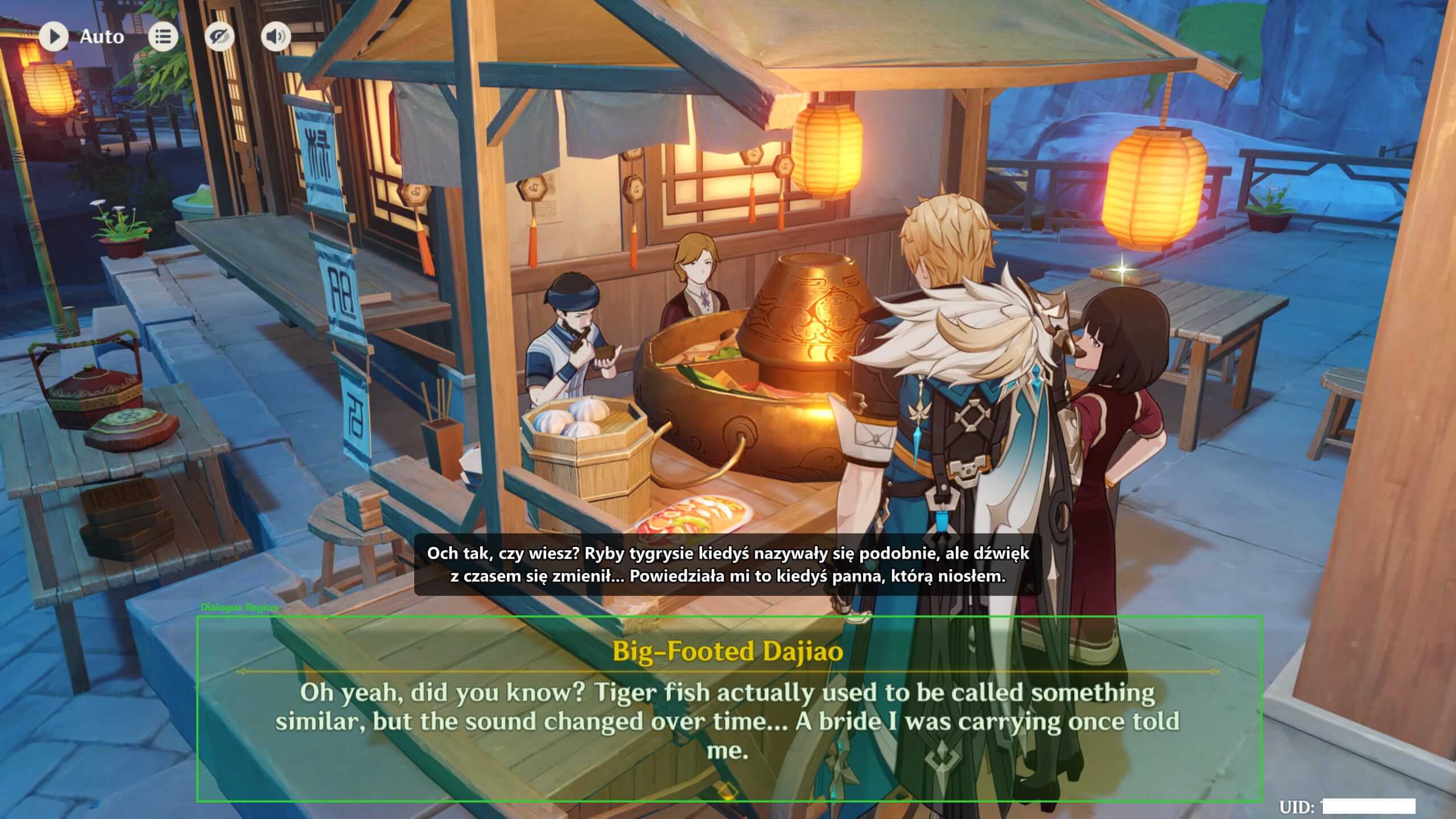
Wypróbuj Kaption
Jeśli grasz w Genshin Impact albo Honkai: Star Rail i chcesz zrozumieć każde zdanie, zamiast mijać dialogi, Kaption jest dla Ciebie. Instalacja zajmuje kilka minut, aplikacja działa lokalnie i nie wymaga grzebania w plikach gry.
Źródła
- [1] PaddleOCR — repozytorium i dokumentacja — https://github.com/PaddlePaddle/PaddleOCR
- [2] ONNX Runtime — oficjalna dokumentacja — https://onnxruntime.ai/docs/
- [3] DirectML — Microsoft Learn — https://learn.microsoft.com/en-us/windows/ai/directml/dml
- [4] DXGI Desktop Duplication API — Microsoft Learn — https://learn.microsoft.com/en-us/windows/win32/direct3ddxgi/desktop-dup-api
- [5] WPF — Windows Presentation Foundation Documentation — https://learn.microsoft.com/en-us/dotnet/desktop/wpf/
- [6] SymSpell — symmetric-delete spellchecking algorithm — https://github.com/wolfgarbe/SymSpell
- [7] Velopack — biblioteka do aktualizacji aplikacji desktopowych — https://velopack.io/
- [8] Cloudflare R2 — S3-compatible object storage — https://developers.cloudflare.com/r2/
- [9] Sentry — obsługa błędów dla .NET — https://docs.sentry.io/platforms/dotnet/
- [10] .NET 10 — oficjalna dokumentacja Microsoft — https://learn.microsoft.com/en-us/dotnet/